Come impostare un monitoraggio completo del server SQL
Oggi, la maggior parte delle applicazioni desktop, mobili, cloud, IoT e di altro tipo si basano pesantemente sui database. Per supportarle, le implementazioni, le capacità e i carichi di lavoro dei server SQL hanno continuato a crescere. Per questo motivo, le aziende devono assicurarsi che i sistemi di dati soddisfino i requisiti prestazionali richiesti.
Di solito, i clienti e gli utenti richiedono un'elevata disponibilità, servizi efficaci e una rapida risoluzione dei problemi. Per questo motivo, il monitoraggio del server SQL fornisce preziose informazioni sullo stato di salute del server, sulle prestazioni e sulle metriche di utilizzo.
Che cos'è un server SQL?
SQL (Structured Query Language) è un linguaggio di interrogazione utilizzato nei database relazionali. È il linguaggio che scrive le query per manipolare o recuperare i dati dai database relazionali.
Un server SQL è lo strumento o il software del sistema di gestione dei database relazionali (RDBMS), come MSSQL di Microsoft, Oracle DB e PostgreSQL, che memorizza, elabora e gestisce i dati.
Inoltre, il server esegue le query e i comandi SQL per manipolare il database relazionale. In pratica, il server SQL ospita il database e le applicazioni SQL, mentre esegue e gestisce tutte le operazioni del database.
Che cos'è il monitoraggio del server SQL?
Il monitoraggio del server SQL è la raccolta e l'analisi continua o in tempo reale delle prestazioni, dell'utilizzo delle risorse, delle metriche di utilizzo e degli eventi di un server di database.
Oltre a identificare problemi di prestazioni, risorse inadeguate o sottoutilizzate e altri problemi, fornisce spunti che gli amministratori possono utilizzare per mettere a punto e migliorare le prestazioni. Uno strumento di monitoraggio ideale ed efficace dovrebbe anche inviare avvisi ogni volta che le metriche monitorate superano determinate soglie definite.
Ciò consente una diagnosi e una risoluzione dei problemi accurate, oltre a una risposta immediata ai problemi. Inoltre, mostra l'utilizzo delle risorse e le tendenze nel tempo, consentendo ai team DBA di pianificare e prepararsi per il futuro.

Chi monitora i server SQL?
I server SQL vengono monitorati dagli amministratori di database (DBA) interni, dai team interni o esterni che si occupano dei server. In generale, qualsiasi organizzazione con un server di database dovrebbe monitorare i propri sistemi, indipendentemente dalle dimensioni.
Un'organizzazione che non dispone di competenze interne adeguate può affidarsi a un DBA di terze parti o in outsourcing per fornire assistenza, se necessario.
Mentre i DBA interni o esterni hanno il compito di assicurare che la piattaforma di database funzioni senza problemi, anche altri dipartimenti dovrebbero partecipare. Ad esempio, se ci sono problemi con la rete, il team dell'infrastruttura IT dovrebbe occuparsene.
Perché è necessario monitorare i server SQL?
Il monitoraggio di qualsiasi server è un'attività indispensabile. Pertanto, il monitoraggio dei server SQL è una delle attività principali che aiutano a ottenere una visione della piattaforma di database. Fornisce informazioni che consentono ai team di risolvere i problemi di disponibilità e prestazioni, evitando così costosi guasti al sistema. Anche se gli obiettivi del monitoraggio possono variare da un'organizzazione all'altra, di seguito sono riportati alcuni motivi principali per cui è essenziale.
Fornisce informazioni sullo stato di salute del server
Ottenete preziose informazioni sullo stato di salute, sulle prestazioni e sulle metriche di utilizzo del server SQL. Il monitoraggio dell'utilizzo delle risorse consente agli amministratori di identificare le opportunità di ottimizzazione e di determinare se è necessario disporre di risorse aggiuntive. Inoltre, i team possono utilizzare le informazioni per mettere a punto i server SQL per ottenere le migliori prestazioni in termini di costi.
Oltre a verificare se il server funziona in modo ottimale, il monitoraggio del server SQL identifica anche le attività insolite. La determinazione del funzionamento del server offre l'opportunità di ottimizzare le prestazioni, di risolvere eventuali problemi e di identificare le opportunità di messa a punto. Inoltre, aiuta a determinare i requisiti per soddisfare le esigenze future.
Ridurre al minimo i problemi di prestazioni e i tempi di inattività
Identificare e risolvere i colli di bottiglia e un'ampia gamma di problemi che potrebbero degradare le prestazioni o causare un'interruzione. I team possono affrontare i problemi di prestazioni in modo tempestivo e rapido, prima che si verifichino interruzioni. Inoltre, il monitoraggio del server SQL consente ai team DBA e IT di ottimizzare i sistemi e di migliorare la velocità e l'esperienza degli utenti, prevenendo al contempo le interruzioni.
Il monitoraggio proattivo o continuo consente ai team di avere uno stato aggiornato del server. Prevenendo l'insorgere di problemi gravi, i team hanno più tempo per lavorare su attività aziendali più importanti invece di risolvere problemi evitabili. Idealmente, il monitoraggio delle prestazioni del database SQL server vi aiuta a mantenere il tuo server SQL e i servizi in funzione senza problemi, riducendo al contempo i rischi di interruzioni impreviste.
Pianificare la crescita futura
Monitorare l'utilizzo delle risorse e le tendenze della capacità per prepararsi e pianificare il futuro. Oltre alle prestazioni, il monitoraggio può fornire altre informazioni utili, fondamentali per pianificare le esigenze future in caso di crescita del database. Ad esempio, può fornire informazioni su un'ampia gamma di metriche, tra cui l'utilizzo dello storage, le query ad alto impatto, le query ad alta intensità di risorse, l'utilizzo del pool di buffering e altri problemi che hanno un impatto sulle prestazioni.
Ridurre i costi dell'infrastruttura
Il monitoraggio consente ai team di ottimizzare le risorse esistenti, riducendo così la necessità di investire in componenti hardware e software aggiuntivi. Ciò consente di massimizzare i componenti dell'infrastruttura e di evitare di investire inutilmente in altre risorse.
Ottimizzare i tempi di attesa e migliorare l'erogazione del servizio
Aumenta i tempi di risposta e le prestazioni del server SQL raccogliendo, analizzando e adottando misure correttive. Oltre a osservare i tempi di risposta, il monitoraggio può rivelare altre informazioni utili, come i limiti di capacità di CPU, memoria o I/O, i lunghi tempi di attesa e altre metriche. Di conseguenza, ciò offre l'opportunità di risolvere i problemi del server, riconfigurare o aggiungere ulteriori risorse e quindi migliorare i tempi di risposta.
Idealmente, il monitoraggio del server SQL è fondamentale per tutte le organizzazioni, siano esse piccole, medie o grandi, che cercano di migliorare le prestazioni delle query del database, di massimizzare i tempi di attività del server, di elaborare le query molto più velocemente e di garantire disponibilità e produttività elevate.
Cosa si deve monitorare in un server SQL?
La comprensione dell'architettura di SQL Server, dei suoi componenti e di come interagiscono tra loro è essenziale, in quanto vi guida su cosa monitorare. Dovete anche sapere perché volete monitorare una particolare metrica o servizio. Inoltre, dato che le cose che si possono monitorare sono tante, è necessario avere un obiettivo da raggiungere. In caso contrario, potreste monitorare metriche e servizi del server SQL che non hanno alcun impatto sulle prestazioni e quindi non supportano il tuo obiettivo.
Le metriche chiave sul lato software includono, ma non solo, le statistiche di attesa, la frammentazione degli indici, la cache del buffer, la sicurezza, ecc. Inoltre, è essenziale tenere traccia delle versioni del software e delle esigenze di manutenzione.
La strategia migliore consiste nell'identificare l'insieme di metriche che ti aiuteranno a raggiungere i tuoi obiettivi di prestazioni, e questo può variare da un'organizzazione all'altra. Di solito vengono monitorate alcune metriche comuni. Queste forniscono informazioni adeguate per eseguire la risoluzione dei problemi e l'ottimizzazione di base. Alcune metriche comunemente monitorate nei server SQL includono l'utilizzo del processore e della memoria, l'attività del disco e il traffico di rete.
Tuttavia, per sistemi complessi e per la risoluzione di problemi avanzati, potrebbe essere necessario monitorare altre metriche per osservare aree specifiche e aiutare a trovare la causa dei problemi.
Oltre ai componenti del server SQL, è necessario monitorare anche altre metriche del sistema operativo. Ad esempio, per un server Windows, è possibile monitorare i seguenti parametri
- Tempo del processore, utilizzo del processore e lunghezza della coda del processore.
- Utilizzo della rete, interfaccia di rete, connessioni utente, ecc.
- Paging, durata delle pagine, letture e scritture di pagine al secondo, scritture pigre, ecc.
- Memoria totale del server, percentuale di hit della cache del buffer, richieste batch, ecc.
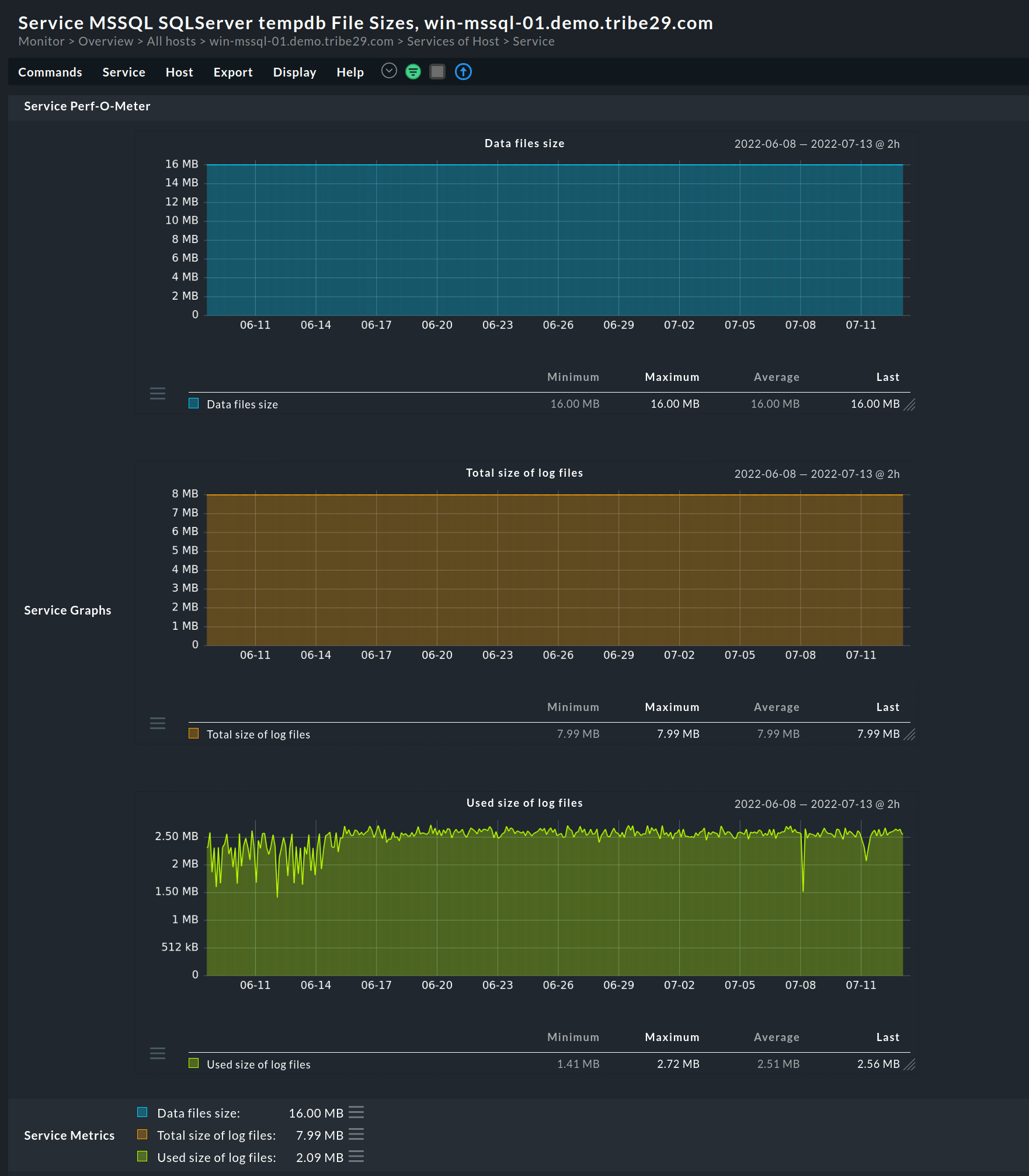
Componenti chiave del server SQL
Un tipico server SQL comprende quattro componenti principali, indipendentemente dal fatto che sia ospitato on-premises o nel cloud. Si tratta del protocollo o della rete, del motore di archiviazione del server SQL, del processore di query e del sistema operativo SQLOS (SQL operating system).
Il processore di query e il motore di archiviazione sono parti del motore di database, che è uno dei componenti principali di un server SQL. In pratica, il ruolo principale del motore di database SQL comprende la creazione e l'esecuzione di stored procedure, trigger, viste e altri oggetti di database.
SQLOS - il sistema operativo SQL
SQLOS è una parte di MSSQL che coordina varie attività tra il server SQL e il sistema operativo. Le funzioni tipiche includono la pianificazione della CPU, la gestione della memoria, i servizi in background, l'I/O logico e altre. In particolare, i processi in background monitorano il sistema per individuare eventuali deadlock, controllando le risorse e liberando la memoria non utilizzata.
Il monitoraggio di SQLOS è essenziale per garantire un utilizzo ottimale delle risorse e per capire quando sono sottoutilizzate o richiedono un aggiornamento. Si tratta di osservare metriche come l'attività della CPU, l'allocazione della memoria e altre.
Protocollo e rete
La rete e i protocolli associati consentono agli utenti di connettersi al server SQL. La velocità di connessione ha un impatto sulle prestazioni complessive e sull'esperienza dell'utente. Per questo motivo, è essenziale monitorare il traffico di rete per vedere se ci sono problemi che potrebbero degradare le prestazioni. Questo aiuta a identificare i segni di un traffico insolito e di colli di bottiglia.
Inoltre, il monitoraggio dei protocolli è essenziale per garantire che siano in ordine e non riducano le prestazioni e l'efficienza del server SQL.
Processore di query
Il processore di query di SQL Server, noto anche come motore relazionale, comprende vari componenti che gestiscono l'esecuzione delle query. In generale, il processore di query recupera i dati dallo storage in base alla query in ingresso, dopodiché li elabora e fornisce i risultati.
Tra le sue funzioni, le prestazioni includono la gestione della memoria, del buffer, dei task, dell'elaborazione delle query e altro ancora. È anche responsabile del blocco e dell'isolamento di pagine, tabelle e righe per i dati richiesti dalla query.
Il monitoraggio prevede l'analisi delle query elaborate, delle risorse utilizzate e del tempo impiegato. Un'altra area è l'analisi dei piani di query che il server utilizza per eseguire le query. Infine, è necessario analizzare la velocità di generazione dei piani di esecuzione.
Motore di archiviazione
Il motore di archiviazione è responsabile della gestione dei file, della gestione delle transazioni, dell'accesso ai vari oggetti del database e altro ancora.
Il monitoraggio del motore assicura che le funzioni siano ottimali. Se non funzionano correttamente o come previsto, i team DBA possono risolvere i colli di bottiglia. Alcune metriche da monitorare sono l'accesso ai file, la capacità di storage, l'allocazione e le prestazioni.
Quali sono le metriche da monitorare su un server SQL?
Il monitoraggio delle prestazioni del server SQL fornisce informazioni utili che consentono di prendere decisioni informate e di ottenere il meglio dalla piattaforma dati. Sebbene esistano numerose metriche, avete la possibilità di scegliere quelle più importanti per il tuo ambiente, le tue applicazioni e i tuoi obiettivi.
In generale, le metriche di SQL server rientrano nelle seguenti cinque categorie principali:
- Transazione
- Metriche della cache del buffer
- Metriche dei blocchi
- Risorse
- Indicizzazione
Metriche Transact SQL (T-SQL)
Il T-SQL è un'estensione dell'SQL convenzionale che aggiunge funzioni supplementari al server SQL. Interagisce con i database relazionali e fornisce funzioni quali il controllo delle transazioni, la gestione degli errori, l'elaborazione delle righe e altro ancora. In pratica, ci sono diverse metriche da monitorare all'interno del T-SQL. Queste includono:
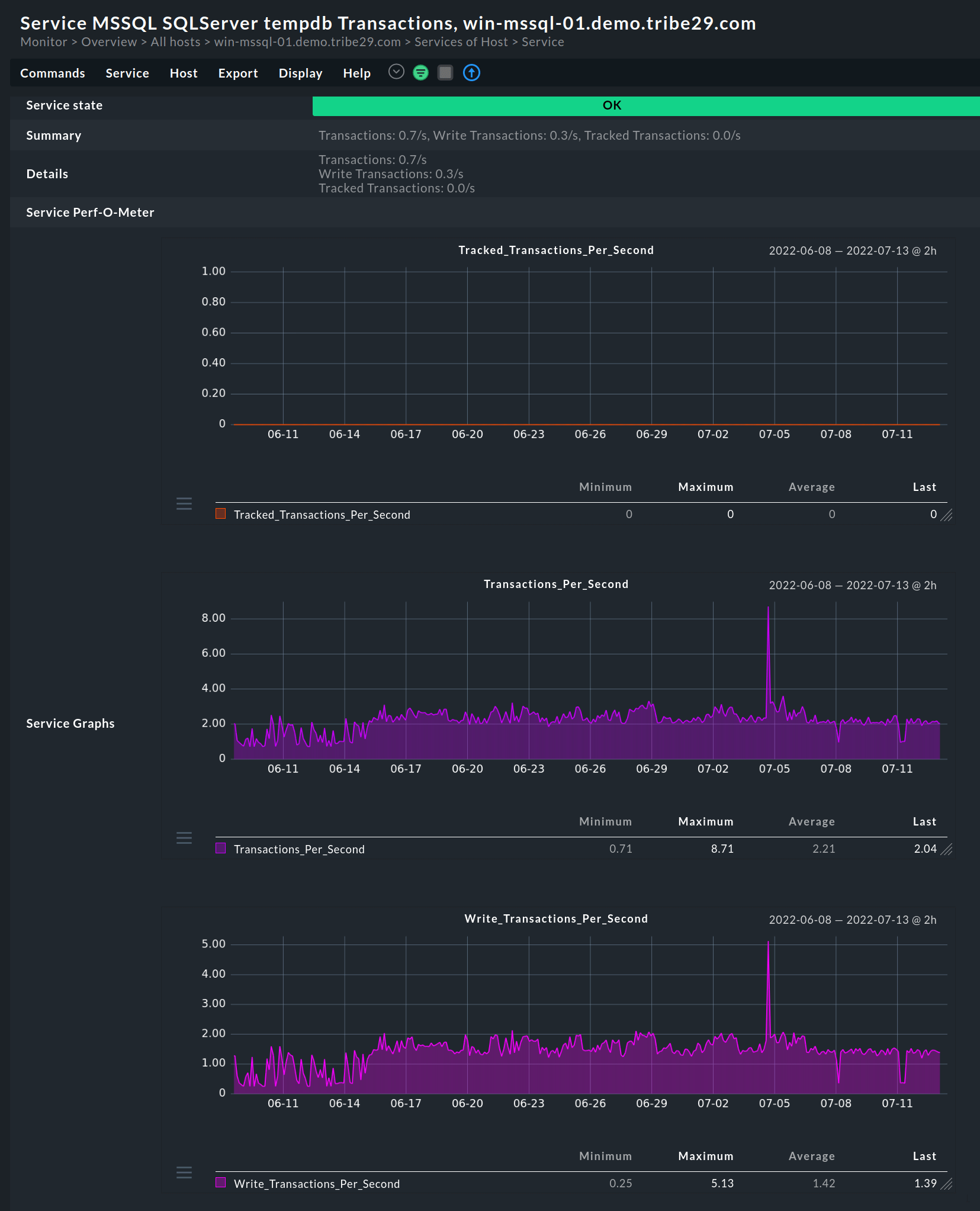
Richieste in batch al secondo
Il monitoraggio delle richieste batch al secondo fornisce una visione di alto livello dell'utilizzo del database. Mostra il numero di richieste batch che il motore del database riceve al secondo.
In pratica, un batch può includere una singola o più istruzioni SQL, ma avrà lo stesso effetto. Inoltre, anche un batch che richiama una stored procedure è sempre considerato una singola richiesta batch.
Per ottenere maggiori informazioni, la prassi migliore è misurare altre metriche correlate, come il tempo trascorso, l'utilizzo della memoria e altre ancora.
Compilazioni SQL al secondo
Le compilazioni al secondo si riferiscono al numero di volte in cui il server compila le query SQL in un secondo. In pratica, il server SQL compila e memorizza le query nella cache prima dell'esecuzione. Idealmente, dovrebbe compilare una query solo una volta e poi riutilizzarla o farti riferimento in futuro.
Il monitoraggio delle compilazioni al secondo mostra se il server fa riferimento alle query nella cache solo una volta o più volte. Se è una sola volta, significa che sta compilando per ogni richiesta batch e il numero di compilazioni al secondo sarà quasi uguale a quello delle richieste batch al secondo. Idealmente, le compilazioni al secondo dovrebbero essere pari o inferiori al 10% del numero totale di richieste batch al secondo.
Ricompilazioni SQL al secondo
Le ricompilazioni SQL al secondo si riferiscono al numero di volte in cui il server ricompila le query in un secondo. Ogni volta che il server SQL viene riavviato o che vengono apportate modifiche ai dati o alla struttura del database, il piano di esecuzione esistente può diventare non valido.
In tal caso, i piani di esecuzione vengono ricompilati. Sebbene la ricompilazione consenta l'esecuzione dei batch T-SQL, è possibile che non si ottengano gli stessi vantaggi in termini di prestazioni, come la riduzione dei tempi di esecuzione, offerti dalla precedente compilazione.
È quindi essenziale osservare l'andamento delle ricompilazioni al secondo e determinare se questo ha un impatto sulle prestazioni. Se si nota un calo delle prestazioni all'aumentare del numero di ricompilazioni al secondo, si può prendere in considerazione la possibilità di regolare la soglia di base per ridurre il tasso.
Ultimo tempo trascorso
L'ultimo tempo trascorso fornisce un'idea del tempo, in microsecondi, che il server SQL ha impiegato per eseguire l'ultima esecuzione di un piano o di un'attività. Di solito, il server SQL compila le query o le istruzioni T-SQL e le memorizza nella cache come piani di esecuzione. Questa attività riduce la latenza e contribuisce a migliorare le prestazioni del server. Monitorando la cache, è possibile stabilire il tempo necessario al server per eseguire le query.
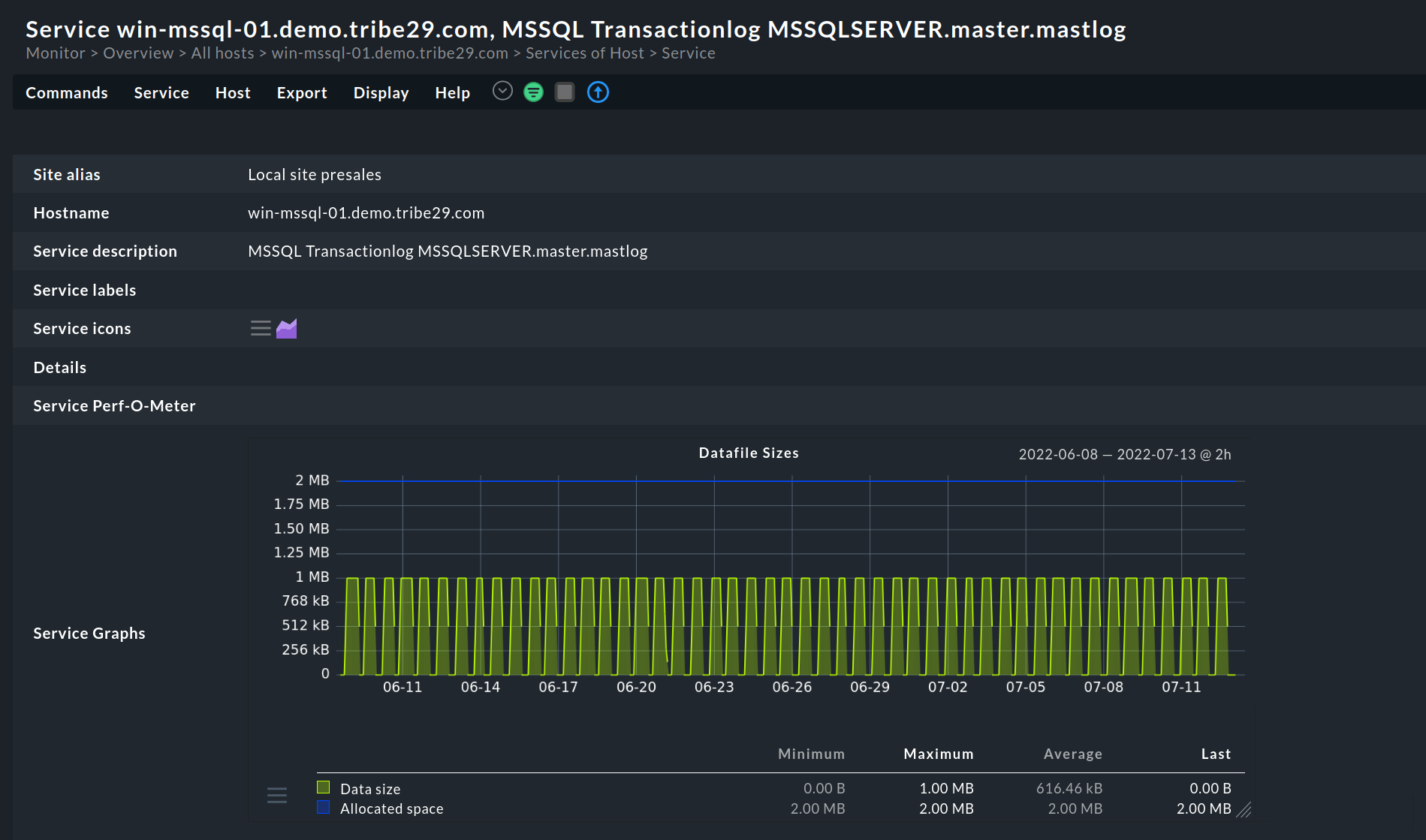
Metriche della cache del buffer
Durante l'esecuzione delle query, la maggior parte dei processi avviene tra il database e la buffer cache. Pertanto, il monitoraggio della buffer cache fornisce informazioni sulle attività tra i due. Idealmente, il server SQL dovrebbe eseguire il maggior numero possibile di operazioni di lettura/scrittura nella memoria anziché nella lenta unità disco.
Le metriche chiave da monitorare includono:
Rapporto di hit della cache del buffer
Il rapporto di hit della cache del buffer confronta il numero di volte in cui il gestore del buffer estrae le pagine dalla cache rispetto a quelle direttamente dal disco. È essenziale monitorare questa metrica e identificare le aree di ottimizzazione.
Di solito, un basso rapporto della cache del buffer può portare a una latenza elevata. È possibile aumentare le dimensioni allocando più memoria. Sebbene non esista una metrica standard per il rapporto buffer cache, si consiglia di avere un minimo di 95 quando si cercano prestazioni elevate. Tuttavia, anche un valore di 90 è adatto a un'ampia gamma di applicazioni.
Pagine di checkpoint al secondo
Le pagine di checkpoint al secondo si riferiscono al numero di pagine che un'azione di checkpoint scrive sul disco al secondo. Una volta modificata, una pagina rimane nella buffer cache come pagina sporca fino al momento del checkpoint. Al momento del checkpoint, il buffer manager sposta tutte le pagine sporche sull'unità disco locale per liberare spazio.
Il monitoraggio delle pagine/sec del checkpoint o della velocità con cui il buffer manager sposta le pagine sul disco è fondamentale per determinare se le risorse sono adeguate o meno.
Aspettativa di vita della pagina
L'aspettativa di vita della pagina mostra come il buffer manager esegue le operazioni di lettura e scrittura nella memoria. Ad esempio, mostra il tempo in secondi in cui una pagina rimane nella cache del buffer senza riferimenti.
Secondo lo standard Microsoft, l'aspettativa di vita della pagina (PLE) non dovrebbe essere inferiore a 300 secondi per ogni 4 GB di memoria allocata al server. Con una maggiore quantità di RAM, è possibile avere una soglia PLE più alta. Per calcolare il valore, utilizzare la formula seguente.
Soglia PLE (Page Life Expectancy) = ((Allocazione memoria buffer (GB)) / 4) * 300
Ad esempio, se si assegnano 10 GB di RAM al server SQL, il valore di PLE sarà
Soglia PLE = (10 / 4) * 300 = 750 secondi
In pratica, il server SQL spesso esegue il flussaggio delle pagine in occasione di un checkpoint o quando è necessario più spazio nella cache del buffer. In quest'ultimo caso, il server SQL eliminerà le pagine a cui si accede di rado.
Il monitoraggio del numero di pagine eliminate al secondo al checkpoint consente di determinare se questa è la causa dell'elevato turnover e quindi della bassa aspettativa di vita.
In questo modo si ha la possibilità di riconfigurare e raggiungere un'impostazione ottimale. Se il monitoraggio mostra una riduzione dei valori di PLE all'aumentare del carico di lavoro, ciò indica che la memoria è inadeguata e che potrebbe essere necessario aggiungerne dell'altra.
Tabella Metriche delle risorse
È essenziale monitorare le tabelle del server SQL e il modo in cui utilizzano le risorse disponibili. Aiuta a determinare se la memoria di sistema, lo storage e le altre risorse sono sufficienti.
Il monitoraggio misura metriche quali la quantità di memoria in kilobyte utilizzata da una tabella. Controlla anche lo spazio occupato dai dati o dagli indici di una tabella.
Tabelle ottimizzate per la memoria
Un server SQL utilizza tabelle ottimizzate per la memoria che supportano transazioni a bassa latenza e ad alta velocità. In genere, le tabelle ottimizzate per la memoria migliorano la velocità di lettura e scrittura.
Il monitoraggio del tasso di soddisfazione delle query dalle tabelle in-memory e delle risorse utilizzate dal processo aiuta a determinare se il processo è ottimale o se può richiedere alcune modifiche.
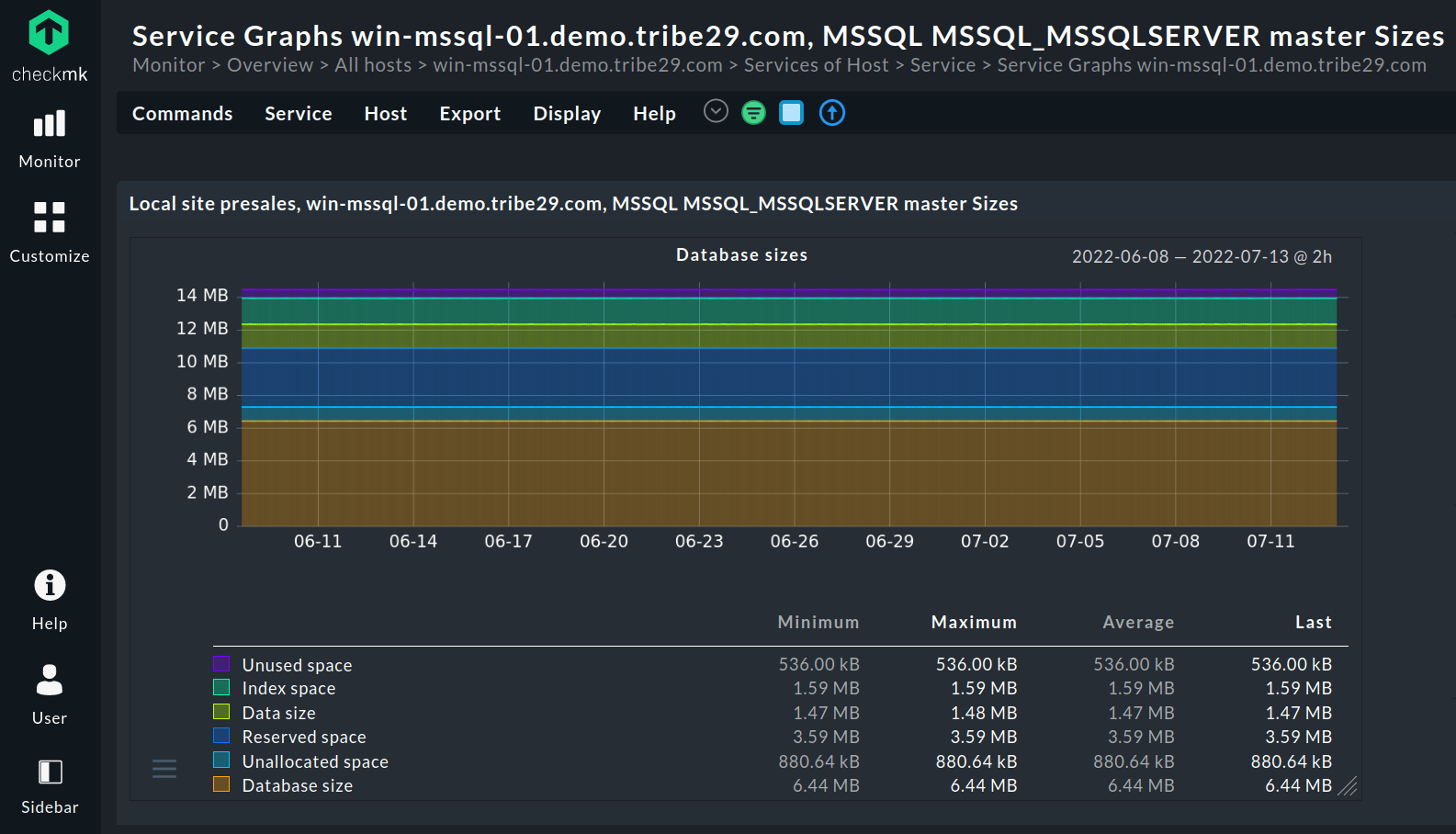
Utilizzo del disco
Il monitoraggio dell'utilizzo del disco vi tiene aggiornati sullo spazio di archiviazione e vi avvisa quando lo spazio è esaurito. In questo modo è possibile intervenire per tempo ed evitare costosi problemi di prestazioni. Il monitoraggio deve individuare la quantità di spazio di archiviazione utilizzato dai dati e dagli indici di una determinata tabella.
Metriche del pool di risorse
Il pool di risorse è una rappresentazione delle risorse fisiche del server, come CPU, memoria, I/O e altre. I pool di risorse possono essere considerati come istanze virtuali del server SQL. Quando si configurano i pool di risorse, gli amministratori spesso impostano alcuni limiti per le risorse di CPU, memoria e I/O del disco in base ai requisiti dell'applicazione. Dopo la configurazione, è necessario garantire un utilizzo efficiente delle risorse e che gli utenti ottengano prestazioni accettabili.
La strategia migliore consiste nel monitorare le risorse di ciascun pool e nel regolarle quando necessario.
Utilizzo della CPU in %
La percentuale di utilizzo della CPU è la percentuale della CPU del server SQL utilizzata da tutti i carichi di lavoro in uno specifico pool di risorse. È possibile specificare la percentuale minima e massima di CPU per un determinato pool di risorse. Monitorando la percentuale di utilizzo della CPU è possibile determinare le tendenze di consumo della maggior parte degli utenti comuni. È inoltre possibile vedere l'impatto delle diverse impostazioni sulle prestazioni e quindi regolare i valori minimi, massimi e il limite massimo (CAP) per ottimizzare e personalizzare le prestazioni del server per attività specifiche.
Operazioni di I/O su disco
Le operazioni di I/O su disco comprendono le attività di lettura e scrittura su disco; due delle metriche principali sono il tempo di ingresso e di uscita. È essenziale monitorare queste metriche, poiché indicano il tempo necessario per leggere o scrivere i dati da e verso il pool di risorse. L'I/O di lettura del disco al secondo si riferisce al numero di operazioni di lettura del disco effettuate nell'ultimo secondo per pool di risorse. Mentre l'I/O di scrittura del disco si riferisce alle operazioni di scrittura del disco.
Lunghezza della coda del disco
La lunghezza della coda del disco si riferisce al numero di richieste di lettura/scrittura in coda per un disco specifico. È essenziale monitorare questa metrica poiché ha un impatto sulle prestazioni. Se il valore è alto, significa che il processo di lettura e scrittura del disco è lento e quindi la latenza è elevata.
Una delle possibili soluzioni è aggiungere più capacità al disco, ma questo deve essere fatto dopo aver controllato altre metriche, come le statistiche sui file e sulle attese, che hanno anch'esse un impatto sulla velocità di lettura e scrittura.
Pagine di memoria al secondo
Le pagine di memoria al secondo sono una metrica utile il cui valore è cruciale per determinare se ci sono errori che potrebbero rallentare le prestazioni. Il monitoraggio è fondamentale per determinare un'ampia gamma di problemi di memoria. Un valore elevato è indice di un'alta velocità di paginazione della memoria da e verso il disco.
Tempo di attesa del latch
Un server SQL utilizza i latches per proteggere i dati in memoria. Inoltre, aiutano a mantenere l'integrità dei dati nelle varie risorse condivise. In genere esistono latches di tipo buffer e non buffer. L'osservazione dei latches consente di visualizzare le statistiche e di identificare le cause dei ritardi.
Quando il sistema di I/O non è in grado di tenere il passo con il ritmo delle richieste attive per un periodo prolungato, si verifica un ritardo di attesa del latch. In questa situazione, ci vuole più tempo per recuperare i dati dall'unità disco e copiarli nella memoria.
Metriche per i lock
Ogni volta che viene eseguita una query su una riga, una pagina o una tabella di un set di dati, i sistemi attivano un blocco che impedisce ad altri processi di modificare i dati su cui si sta lavorando.
Attese di blocco al secondo
Un numero elevato di attese al secondo significa che il sistema dovrà attendere più a lungo per lo sblocco e potrebbe causare problemi di prestazioni.
Anche se un numero elevato di blocchi è indice di un problema, ciò dipende dalla capacità del server. Ad esempio, un server che gestisce circa 100 richieste al secondo avrà meno blocchi rispetto a uno con 2 milioni di aggiornamenti al secondo.
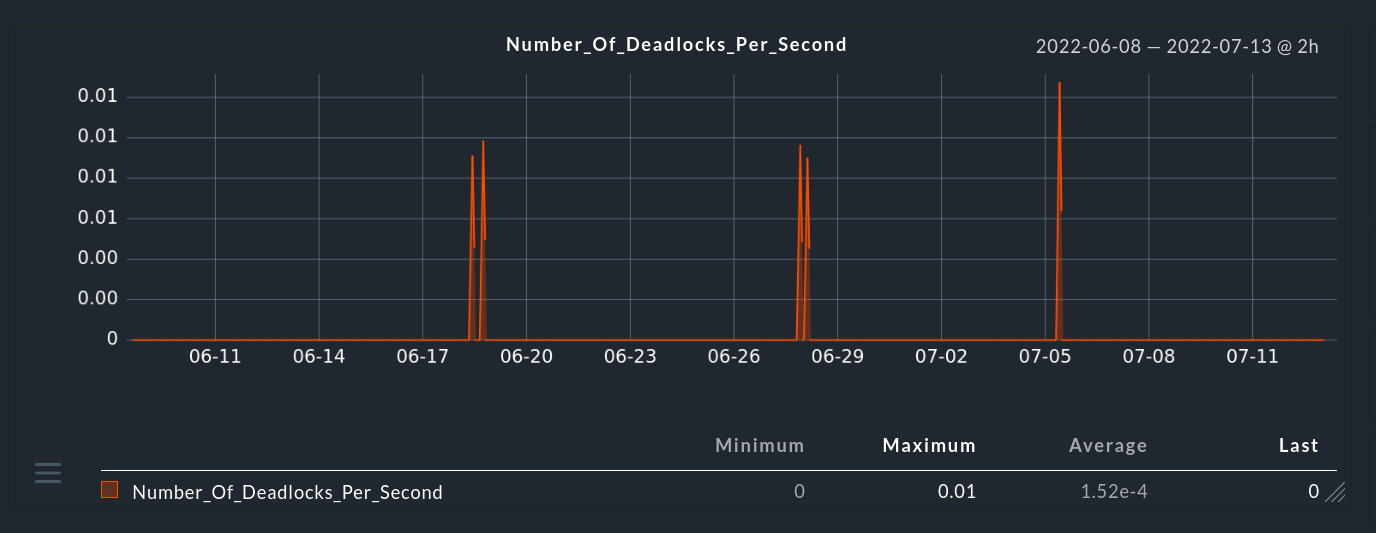

Tempo medio di attesa del blocco
Le risorse a cui accedono più utenti sono solitamente bloccate dal server SQL per evitare letture errate. Per evitare che altri utenti attendano troppo a lungo per accedere alle risorse, il tempo medio di attesa del blocco deve essere il più breve possibile.
Il monitoraggio dei tempi medi di attesa dei blocchi offre l'opportunità di identificare i ritardi e le query che impiegano più tempo per rilasciare i blocchi.
Indicizzazione
L'indicizzazione migliora la velocità di ricerca dei dati nel database. Quando la quantità di dati aumenta, l'indice cresce e il server SQL può dividere l'indice per renderlo più efficiente. Tuttavia, questo aumenta l'utilizzo delle risorse e può portare a inefficienze.
Il monitoraggio degli indici consente ai team di osservare con attenzione le metriche relative all'indice e di intraprendere le azioni necessarie per garantire una gestione efficiente delle query.
Metriche da monitorare
Pagine suddivise al secondo
Il monitoraggio controlla il numero di suddivisioni di pagina che si verificano al secondo a causa dell'aumento dei dati. Di solito, gli indici sono memorizzati sulle pagine proprio come i dati. Quando i dati crescono, gli indici aumentano. Ma quando la pagina diventa troppo piena, il server SQL crea un'altra pagina di indice e sposta alcune righe dalla pagina piena a quella nuova.
Poiché questo processo può consumare una quantità significativa di risorse, è importante monitorare e intervenire se il numero di suddivisioni al secondo è elevato. Purtroppo, un numero eccessivo di suddivisioni di pagine può ridurre le prestazioni, in quanto porta alla frammentazione.
Frammentazione %
La frammentazione si verifica quando l'ordine dei dati nell'indice differisce dall'ordine di memorizzazione dei dati sul disco. In genere, questo comporta un rallentamento delle prestazioni, poiché il sistema ha bisogno di più tempo per far corrispondere l'indice ai dati corrispondenti.
Tra le cause della frammentazione vi sono la crescita dei dati, la suddivisione delle pagine e le modifiche apportate all'indice in seguito all'aggiornamento, all'inserimento e all'eliminazione di voci.
Il monitoraggio è un modo per determinare l'entità della frammentazione e una metrica utile da osservare è la percentuale di frammentazione. Questa si riferisce alla percentuale di pagine ordinate nell'indice. Se la frammentazione è elevata, rallenta le prestazioni e si può intervenire ricostruendo l'indice.
Metriche di connessione
Il mantenimento di una connessione client affidabile è fondamentale per garantire la corretta esecuzione delle query. È quindi necessario monitorare le connessioni e risolvere i problemi per garantire prestazioni e disponibilità affidabili.
Connessioni utente
La metrica si riferisce al numero di utenti connessi con successo al server SQL al momento della misurazione. Il monitoraggio delle connessioni e la correlazione con altre metriche offre l'opportunità di scoprire aree di ottimizzazione.
Come si inizia a monitorare l'ambiente SQL Server?
Idealmente, la pratica migliore e più efficace è quella di utilizzare una soluzione di monitoraggio affidabile. In questo modo avrete tutto in un unico posto e molti approfondimenti. Altrimenti, si può accedere a ogni sistema e controllare manualmente, ma in questo modo si ottengono meno dati, nessuna correlazione, ecc.
Anche se è possibile monitorare manualmente alcuni problemi, questa operazione è macchinosa e inefficace, soprattutto se l'ambiente è composto da molti server SQL.
Se si utilizza uno strumento di monitoraggio, è necessario avere una buona strategia, che richiede di seguire alcuni passaggi collaudati.
Passo 1: scoprire i server SQL
Scoprite tutti i server SQL da monitorare. La scoperta iniziale, soprattutto se si tratta di un ambiente nuovo, aiuta a identificare il numero e la posizione fisica dei server SQL nell'ambiente.
Fase 2: Creare una panoramica dell'ambiente SQL Server
Mappate tutte le risorse e i componenti chiave che compongono e supportano l'ecosistema del server SQL. Una delle migliori pratiche consiste nell'identificare tutti i componenti dell'infrastruttura SQL e nel documentarli.
In seguito, il monitoraggio e la gestione saranno molto più semplici e ancora più efficaci se si è riusciti a individuare il maggior numero possibile di asset e componenti.
Fase 3: Determinare le metriche da monitorare
Stabilite le metriche del server SQL da monitorare. Di solito, la piattaforma di database ha così tante metriche che è possibile monitorare e ottenere informazioni su un'ampia gamma di aree chiave dell'ecosistema.
Idealmente, è necessario tenere traccia delle principali risorse hardware e software, nonché di altre metriche critiche delle prestazioni. I componenti tipici includono CPU, RAM, unità disco di archiviazione, rete e altri. Inoltre, aiuta a monitorare la capacità, consentendo di pianificare gli aggiornamenti futuri.
Oltre all'hardware, è necessario tenere traccia delle configurazioni software e del loro impatto sulle prestazioni.
Fase 4: Identificare uno strumento di monitoraggio efficace
Cercate gli strumenti più adatti ai tuoi obiettivi di monitoraggio. Poiché le implementazioni dei server SQL possono variare da un'organizzazione all'altra, è fondamentale definire una strategia di monitoraggio che catturi al meglio tutti i componenti chiave che hanno un impatto diretto sulle prestazioni del database.
Fase 5: Avviare il monitoraggio mentre si perfeziona la strategia
Implementa il tuo strumento di monitoraggio e la tua strategia per determinare lo stato generale della tua piattaforma di database. Monitora tutte le metriche chiave che influiscono sulla salute e sulle prestazioni del server SQL.
Valutare la strategia di monitoraggio del server SQL e apportare modifiche per migliorarne l'efficienza. A seconda delle configurazioni, potreste iniziare a ricevere molti avvisi, alcuni dei quali sono falsi allarmi, duplicati e altro.
Il sovraccarico di avvisi finirà per causare tempi di risposta lenti e l'impossibilità di affrontare adeguatamente i problemi principali.
Qual è il miglior software di monitoraggio di SQL Server?
È buona norma implementare strumenti di monitoraggio del server SQL efficaci che forniscano avvisi solo in caso di problemi. Una buona soluzione di monitoraggio dovrebbe anche avvisare in caso di utilizzo eccessivo di risorse come CPU, RAM e disco, nonché in caso di problemi con altre metriche di prestazione.
È importante che uno strumento fornisca un monitoraggio preciso con il minimo sforzo e che supporti una varietà di database e ambienti. Se l'uso di uno strumento di monitoraggio richiede troppo tempo, gli amministratori di sistema dei database sono sottoposti a un'immensa pressione di tempo e questo porta a lacune nel monitoraggio dei database.
Uno dei migliori strumenti di monitoraggio SQL è Checkmk. Questo strumento è dotato di un'ampia gamma di plug-in di monitoraggio, che rendono molto semplice la raccolta e l'analisi dei dati metrici.
Inoltre, questo strumento facile da configurare e flessibile si integra bene con Microsoft SQL, Oracle Database, PostgreSQL, MariaDB e IBM DB2. Ciò consente di impostare una soluzione di monitoraggio completa per i server SQL con pochi clic. In questo modo è possibile configurare e monitorare rapidamente i server SQL con Checkmk.
Tutti i plug-in necessari sono accessibili tramite l'interfaccia grafica di Checkmk e possono essere installati con pochi clic.
Inoltre, Checkmk è altamente scalabile e adatto a tutti i tipi di organizzazioni. Ad esempio, Swisscom utilizza Checkmk per monitorare senza problemi enormi database Oracle con diverse migliaia di servizi per host.
Con Checkmk è possibile monitorare anche i database nel cloud: ad esempio, è possibile monitorare facilmente AWS RDS. Sono disponibili anche integrazioni per il monitoraggio di database NoSQL come Redis, MongoDB o Couchbase.
Checkmk è anche adatto all'uso da parte di più team e fornisce agli amministratori di database un facile accesso al mondo DevOps grazie alla sua profonda integrazione con Prometheus. Allo stesso tempo, anche gli sviluppatori beneficiano dei dati di Checkmk e possono monitorare le interazioni tra database e applicazioni.
Problemi comuni nel monitoraggio dei server SQL
Le soluzioni fai-da-te o costruite in casa possono apparire come alternative favorevoli e a basso costo per il monitoraggio dei server. Tuttavia, alla lunga potrebbero risultare inefficaci, dispendiose in termini di tempo e di denaro.
Sebbene alcune organizzazioni scelgano di utilizzare soluzioni di monitoraggio manuali o sviluppate internamente per ridurre i costi, questo approccio è inefficace, soprattutto in presenza di molti casi. Un altro problema degli strumenti interni è l'incapacità di monitorare completamente i server SQL distribuiti su infrastrutture on-premise, cloud e ibride.
La mancanza di un adeguato strumento di monitoraggio del server SQL impedisce il funzionamento efficiente del sistema di database. In particolare, gli amministratori possono ritardare l'implementazione di nuovi processi, soprattutto se passano la maggior parte del tempo a svolgere attività manuali e dispendiose.
A causa dell'inefficacia, i DBA si sforzeranno di risolvere i problemi più frequenti, invece di dedicare il loro tempo a trovare e risolvere le cause principali.
Il problema delle soluzioni di monitoraggio del server SQL fai-da-te
Sebbene l'implementazione di una soluzione di monitoraggio del server SQL fai-da-te possa sembrare attraente e un modo per ridurre i costi, presenta diverse sfide. Per questo motivo, a lungo termine potrebbe non dare i risultati sperati, e di seguito sono elencati alcuni dei problemi che probabilmente incontrerete.
Raccoglie troppi dati
Raccolta di troppi dati: Alcuni strumenti raccolgono molti dati, comprese informazioni che non riguardano le prestazioni del server SQL. L'analisi di questi dati richiede più tempo, riducendo così l'efficienza degli sforzi di monitoraggio. Uno strumento ideale deve essere veloce e al tempo stesso fornire informazioni pertinenti e, preferibilmente, approfondimenti praticabili sui dati relativi alle prestazioni.
Raccoglie informazioni metriche inadeguate
Raccolta di informazioni metriche inadeguate: Allo stesso modo, uno strumento che fornisce poche informazioni potrebbe non dare risultati e quindi risultare inefficace. Senza informazioni adeguate, i team DBA avranno difficoltà a trarre conclusioni corrette o efficaci.
Inoltre, potrebbero spendere molto tempo e fatica inutilmente per risolvere un piccolo problema che richiede un investimento minore.
Aumenta il carico di lavoro della gestione
Il monitoraggio aumenta notevolmente il carico di lavoro amministrativo. Provoca un numero eccessivo di avvisi inutili che i DBA devono gestire e che fanno perdere molto tempo. Con avvisi precisi, questo tempo potrebbe essere utilizzato per altre attività.
Utilizza più risorse
Sebbene l'impatto dello strumento di monitoraggio sia trascurabile sulle prestazioni del server SQL, in alcuni casi l'utilizzo delle risorse è elevato. L'impatto dipende in larga misura dall'ambiente, se il server è ospitato internamente, nel cloud o in un'infrastruttura IT ibrida. Ad esempio, nel caso di un server basato su cloud, lo strumento di monitoraggio può utilizzare una notevole larghezza di banda.
Il traffico di rete dello strumento può finire per competere con le applicazioni del database, riducendo così la velocità di risposta. Allo stesso modo, uno strumento che utilizza più CPU e memoria peggiora le prestazioni. Di solito, questo è un problema quando le risorse sono limitate.
Aumenta il debito tecnico
Oltre a dedicare tempo allo sviluppo di uno strumento di monitoraggio interno, i costi di manutenzione e altre sfide potrebbero essere elevati. Le soluzioni interne sono soggette a molti problemi, tra cui la mancanza di documentazione, gli sviluppatori che lasciano l'azienda, i problemi di scalabilità e altro ancora.
Ad esempio, senza documentazione, potrebbe non essere possibile sapere quale sviluppatore ha lavorato su una determinata parte della soluzione. Inoltre, quando i programmatori lasciano l'azienda, la manutenzione della soluzione diventa una sfida o molto costosa.
Considerazioni finali sul monitoraggio dei server SQL
I database sono diventati componenti critici delle attuali applicazioni desktop, mobili, industriali e di altro tipo. Garantire un'elevata efficienza e disponibilità è quindi fondamentale per fornire un'esperienza utente e operazioni aziendali eccellenti.
Le cattive prestazioni dei server SQL non solo riducono l'efficienza delle operazioni interne dell'organizzazione, ma anche dei servizi ai clienti esterni.
Uno dei modi migliori per tenere sotto controllo le prestazioni, rilevare i problemi e offrire ai DBA l'opportunità di fornire soluzioni rapide è l'implementazione di un efficace monitoraggio del server SQL.
Tuttavia, per ottenere un monitoraggio continuo del server SQL, è necessario uno strumento efficace in grado di raccogliere tutte le metriche rilevanti e di fornire informazioni utili.
Idealmente, il monitoraggio consente agli amministratori di identificare rapidamente i problemi di prestazioni critici sul server. In particolare, uno strumento efficace offre la possibilità di eseguire il drill-down e di analizzare un'ampia gamma di metriche delle prestazioni.
FAQ
Microsoft SQL Server può essere monitorato da strumenti automatizzati come Checkmk. Questo strumento, completo e altamente personalizzabile, è in grado di monitorare un'ampia gamma di metriche, raccogliere dati preziosi e fornire informazioni utili. Poiché l'obiettivo del monitoraggio può variare da un ambiente e da un'applicazione all'altra, è possibile personalizzare Checkmk per monitorare solo gli strumenti rilevanti per i propri obiettivi.
Lo strumento vi aiuta a impostare avvisi precisi, a visualizzare le prestazioni, a identificare i problemi e a ottimizzare le risorse per ottenere il miglior ROI. Inoltre, consente di gestire i rischi di performance esistenti e potenziali.
Il monitoraggio delle attività può essere avviato in vari modi. Tra questi vi sono:
- Facendo clic sull'icona del monitor attività nella barra degli strumenti di SQL Server Management Studio.
- Andando in Esplora oggetti, facendo clic con il tasto destro del mouse sull'istanza del server SQL e selezionando Monitoraggio attività.
- Utilizzando la scorciatoia da tastiera Ctrl+Alt+A.
- Impostando l'apertura automatica del Monitor attività all'avvio di SQL Server Management Studio.